[TOC]
1、常用命令
| 命令 | 说明 |
|---|---|
| hive --version | 查看hive版本 |
| select version() | 查看hive版本 |
| show databases | 查看数据库 |
| show tables like 'test_*' | 查看表 |
| show functions | 查看函数 |
| show create table tbname | 查看建表语句 |
| show partitions tbname | 查看分区 |
| desc tbname | 查看表字段注释 |
| desc extended tbname | 查看表字段注释 |
| desc formatted tbname | 查看表字段注释 |
| explain sql | 查看执行计划 |
| show locks extended | 查看锁 |
| unlock table tbname | 释放锁 |
| msck repair table tbname | 刷新所有分区元数据 |
| drop database db_name cascade | 删表删库 |
| hive -hiveconf bizdate=20180101 -f test.hql | 传参执行 hql 文件 |
| ANALYZE TABLE tablename COMPUTE STATISTICS -- noscan | 更新统计信息 |
| alter table tablename set FILEFORMAT orc | 修改表存储格式 |
| alter table tablename set tblproperties('EXTERNAL'='TRUE'); | 修改为外部表 |
2、常用调优设置
- 启用本地模式
set hive.exec.mode.local.auto=true;
set hive.exec.mode.local.auto.inputbytes.max=52428800;
set hive.exec.mode.local.auto.input.files.max=10;
fetch 模式
- none :全部查询走 mapreduce
- minimal(默认): 一般的 limit 查询,不走 mapreduce
- more :一般的 limit 查询、where过滤等都不走 mapreduce
set hive.fetch.task.conversion=more;
- 开启动态分区写入
set hive.exec.dynamici.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions=10000;
set hive.exec.max.dynamic.partitions.pernode=10000;
- 使用spark引擎
-- spark引擎参数
-- 内存占用 cores * memory * instances
-- 核数占用 cores * instances + 1 (driver)
set hive.execution.engine=spark;
set spark.executor.cores=2;
set spark.executor.memory=1G;
set spark.executor.instances=8;
- 设置 map
-- hive 不能直接设置 map 数,只能通过设置块大小间接实现控制 map 数
-- 合并输入端的小文件,减少map数
set mapred.max.split.size=256000000;
set mapred.min.split.size.per.node=256000000;
set mapred.min.split.size.per.rack=256000000;
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
- 设置 reduce
-- 设置每个 reduce 处理的数据量 默认 64 M
set hive.exec.reducers.bytes.per.reducer = 67108864
-- 设置 reduce 个数上限
set hive.exec.reducers.max = 20;
-- 直接设置 reduce 的个数
set mapred.reduce.tasks = 15;
- 其它设置
--Map 端部分聚合,相当于Combiner
set hive.map.aggr = true;
--有数据倾斜的时候进行负载均衡
set hive.groupby.skewindata=true;
--设置内存缓冲区大小,很多时候可以解决内存不足问题
set io.sort.mb=10;
--最大可用内存
set mapreduce.map.java.opts=-Xmx2048m;
set mapreduce.reduce.java.opts=-Xmx2048m;
--join优化 数据量大时使用
set hive.auto.convert.join=true;
--设置任务数
set mapred.reduce.tasks=20;
--任务并行,会消耗更多资源
set hive.exec.parallel=true;
--jvm重用
set mapred.job.reuse.jvm.num.tasks=10;
3、常用建表语句
分区表
CREATE TABLE `test.table_partition`( `id` string COMMENT '主键', `name` string COMMENT '名称' ) COMMENT '信息表' PARTITIONED BY ( `bizdate` string COMMENT '业务日期', `province` string COMMENT '省份')建表时指定分隔符
CREATE TABLE `test.table_terminated`( `id` string COMMENT '主键', `name` string COMMENT '名称') row format delimited fields terminated by '\001' lines terminated by '\n'建表时指定分隔符(多字符分割)
CREATE TABLE `test.table_terminated_mul`( `id` string COMMENT '主键', `name` string COMMENT '名称') row format serde 'org.apache.hadoop.hive.contrib.serde2.MultiDelimitSerDe' WITH SERDEPROPERTIES ("field.delim"="##");建表时指定分隔符 (正则序列化)
CREATE TABLE `test.table_regex`( `id` string COMMENT '主键', `name` string COMMENT '名称') row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe' WITH SERDEPROPERTIES ("input.regex" = "(.*)-(.*)-(.*)");snappy 压缩表
CREATE EXTERNAL TABLE `test.table_snappy`( `id` string COMMENT '主键', `name` string COMMENT '名称') STORED AS Parquet TBLPROPERTIES ("orc.compress"="SNAPPY");外部表,访问 hbase
CREATE EXTERNAL TABLE test.table_hbase( `keyid` string COMMENT 'from deserializer', `title` string COMMENT 'from deserializer', `bizdate` string COMMENT 'from deserializer') ROW FORMAT SERDE 'org.apache.hadoop.hive.hbase.HBaseSerDe' STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ( 'hbase.columns.mapping'=':key,cf:title,cf:bizdate', 'serialization.format'='1') TBLPROPERTIES ( 'hbase.table.name'='test_list')
- 外部表,访问 elasticsearch
--根据 id 追加更新,无法删除
add jar hdfs:/user/hive/es_hadoop/elasticsearch-hadoop-5.4.3/dist/elasticsearch-hadoop-hive-5.4.3.jar;
DROP TABLE IF EXISTS test.table_es;
CREATE EXTERNAL TABLE IF NOT EXISTS test.table_es(
id string comment '技术主键'
,name string comment '案件名称'
) comment '结果信息'
STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler'
TBLPROPERTIES('es.resource' = 'idx_f_gf_ent_penalty_info/f_gf_ent_penalty_info',
'es.nodes'='172.16.123.80 ',
'es.port'='8200',
'es.mapping.id' = 'id',
'es.write.operation'='upsert',
'es.net.http.auth.user'='elastic',
'es.net.http.auth.pass'='changeme'
);
4、常用语句
- 数据导入
LOAD DATA LOCAL INPATH '/home/getway/tmp/way/data_test.txt'
OVERWRITE INTO TABLE spider.test_way_20200818 ;
- 数据导出
INSERT OVERWRITE LOCAL DIRECTORY '/home/getway/tmp/way'
ROW FORMAT DELIMITED FIELDS TERMINATED by ','
select * from spider.test_way_20200818 ;
- 创建临时表
create temporary table as select id from tb;
- 加字段
分区表添加字段,需要使用 CASCADE
alter table test20200415 add columns (name string, age string) CASCADE;
- 删除外部表数据
ALTER TABLE xxx SET TBLPROPERTIES('EXTERNAL'='False'); drop table xxx;
- hive 正则查找替换(注释使用 \,分号使用 \073 表示)
select regexp_replace(regexp_extract('asdas.doc','.docx|.xlsx|.xls|.pdf|.doc',0),'\\.','')
- 截取
SELECT split("6.5-8.5", '-')[0], split("6.5-8.5", '-')[1]
- 侧视图( 列转行)
with tt as (
select '0001/0002/0003' as file_id, '1' as key
union all select '0004' as file_id, '2' as key
)
select *
from tt
lateral view explode(split(file_id,'/')) b AS col5
- 行合并
with tt AS(
select 'aaa' as a,'aaa' as b
union all select '1234' as a,'cccc' as b
)
select concat_ws(',',collect_set(a)) as ua, concat_ws(',',collect_set(b)) as ub
from tt
- json 解析函数 (get_json_object)
with json_test as (
select '{"message":"2015/12/08 09:14:4","server": "passport.suning.com","request": "POST /ids/needVerifyCode HTTP/1.1"}' as js
)
select get_json_object(js,'$.message'), get_json_object(js,'$.server') from json_test;
- json 解析函数 (json_tuple)
with json_test as (
select '{"message":"2015/12/08 09:14:4","server": "passport.suning.com","request": "POST /ids/needVerifyCode HTTP/1.1"}' as js
)
select a.*
from json_test
lateral view json_tuple(js,'message','server','request') a as f1,f2,f3;
5、元数据
- hive元数据查看
select * from(
select a.TBL_NAME,
sum(case when param_key='numRows' then param_value else 0 end) 'rownum',
sum(case when param_key='numRows' then 1 else 0 end) 'part_num' ,
sum(case when param_key='totalSize' then param_value else 0 end)/1024/1024/1024 'totalSize',
sum(case when param_key='numFiles' then param_value else 0 end) 'numFiles'
from TBLS a
left join TABLE_PARAMS b on a.TBL_ID = b.TBL_ID
where a.TBL_NAME not like '%_hbase'
group by a.TBL_NAME
) as a order by a.totalSize desc
- 分区表,元数据不一致处理,统一更新
-- select T1.TBL_NAME, T4.PART_NAME, T5.CD_ID, T3.CD_ID
-- from TBLS T1,DBS T2,SDS T3,PARTITIONS T4, SDS T5
UPDATE TBLS T1,DBS T2,SDS T3,PARTITIONS T4, SDS T5
SET T5.CD_ID = T3.CD_ID
WHERE T2.NAME = 'edw'
AND T1.TBL_NAME = 'test20200415'
AND T1.DB_ID = T2.DB_ID
AND T1.SD_ID = T3.SD_ID
AND T1.TBL_ID=T4.TBL_ID
AND T4.SD_ID = T5.SD_ID
and T5.CD_ID <> T3.CD_ID
6、自定义函数
- UDF 一进一出 python 实现
- UDAF 聚合函数,多进一出,类似于:count/max/min python 实现
- UDTF 一进多出,类似 lateral view explode() python 实现
7、Hive 架构
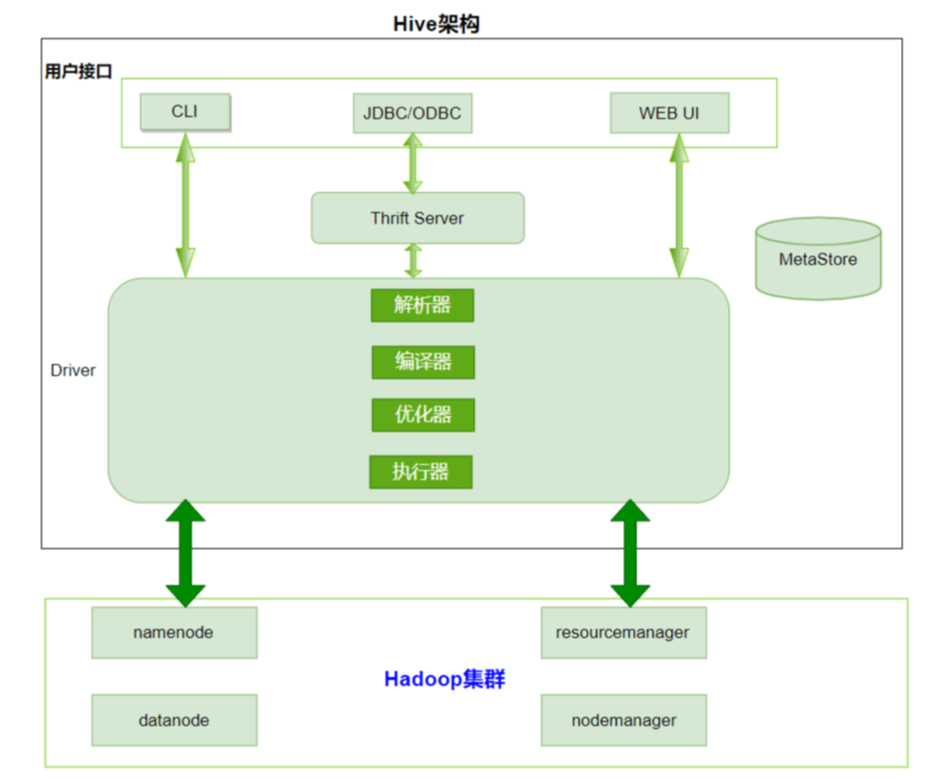
- 解析器(SQL Parser)
- 将SQL字符串转换成抽象语法树AST
- 对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误
- 编译器(Physical Plan):将AST编译生成逻辑执行计划
- 优化器(Query Optimizer):对逻辑执行计划进行优化
- 执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说默认就是mapreduce任务